Tutorial: Reduced order model (POD-RBF or POD-NN) for parametric problems#
![]()
The tutorial aims to show how to employ the PINA library in order to apply a reduced order modeling technique [1]. Such methodologies have several similarities with machine learning approaches, since the main goal consists in predicting the solution of differential equations (typically parametric PDEs) in a real-time fashion.
In particular we are going to use the Proper Orthogonal Decomposition with either Radial Basis Function Interpolation(POD-RBF) or Neural Network (POD-NN) [2]. Here we basically perform a dimensional reduction using the POD approach, and approximating the parametric solution manifold (at the reduced space) using an interpolation (RBF) or a regression technique (NN). In this example, we use a simple multilayer perceptron, but the plenty of different architectures can be plugged as well.
References#
Rozza G., Stabile G., Ballarin F. (2022). Advanced Reduced Order Methods and Applications in Computational Fluid Dynamics, Society for Industrial and Applied Mathematics.
Hesthaven, J. S., & Ubbiali, S. (2018). Non-intrusive reduced order modeling of nonlinear problems using neural networks. Journal of Computational Physics, 363, 55-78.
Let’s start with the necessary imports. It’s important to note the
minimum PINA version to run this tutorial is the 0.1.
## routine needed to run the notebook on Google Colab
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False
if IN_COLAB:
!pip install "pina-mathlab"
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('tableau-colorblind10')
import torch
import pina
from pina.geometry import CartesianDomain
from pina.problem import ParametricProblem
from pina.model.layers import PODBlock, RBFBlock
from pina import Condition, LabelTensor, Trainer
from pina.model import FeedForward
from pina.solvers import SupervisedSolver
print(f'We are using PINA version {pina.__version__}')
We are using PINA version 0.1.1
We exploit the Smithers library to
collect the parametric snapshots. In particular, we use the
NavierStokesDataset class that contains a set of parametric
solutions of the Navier-Stokes equations in a 2D L-shape domain. The
parameter is the inflow velocity. The dataset is composed by 500
snapshots of the velocity (along \(x\), \(y\), and the
magnitude) and pressure fields, and the corresponding parameter values.
To visually check the snapshots, let’s plot also the data points and the reference solution: this is the expected output of our model.
from smithers.dataset import NavierStokesDataset
dataset = NavierStokesDataset()
fig, axs = plt.subplots(1, 4, figsize=(14, 3))
for ax, p, u in zip(axs, dataset.params[:4], dataset.snapshots['mag(v)'][:4]):
ax.tricontourf(dataset.triang, u, levels=16)
ax.set_title(f'$\mu$ = {p[0]:.2f}')
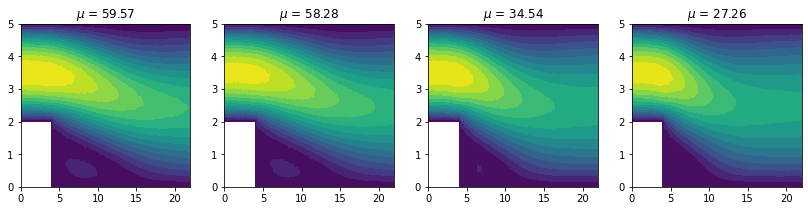
The snapshots - aka the numerical solutions computed for several
parameters - and the corresponding parameters are the only data we need
to train the model, in order to predict the solution for any new test
parameter. To properly validate the accuracy, we initially split the 500
snapshots into the training dataset (90% of the original data) and the
testing one (the reamining 10%). It must be said that, to plug the
snapshots into PINA, we have to cast them to LabelTensor
objects.
u = torch.tensor(dataset.snapshots['mag(v)']).float()
p = torch.tensor(dataset.params).float()
p = LabelTensor(p, labels=['mu'])
u = LabelTensor(u, labels=[f's{i}' for i in range(u.shape[1])])
ratio_train_test = 0.9
n = u.shape
n_train = int(u.shape[0] * ratio_train_test)
n_test = u - n_train
u_train, u_test = u[:n_train], u[n_train:]
p_train, p_test = p[:n_train], p[n_train:]
It is now time to define the problem! We inherit from
ParametricProblem (since the space invariant typically of this
methodology), just defining a simple input-output condition.
class SnapshotProblem(ParametricProblem):
output_variables = [f's{i}' for i in range(u.shape[1])]
parameter_domain = CartesianDomain({'mu': [0, 100]})
conditions = {
'io': Condition(input_points=p_train, output_points=u_train)
}
poisson_problem = SnapshotProblem()
We can then build a PODRBF model (using a Radial Basis Function
interpolation as approximation) and a PODNN approach (using an MLP
architecture as approximation).
POD-RBF reduced order model#
Then, we define the model we want to use, with the POD (PODBlock)
and the RBF (RBFBlock) objects.
class PODRBF(torch.nn.Module):
"""
Proper orthogonal decomposition with Radial Basis Function interpolation model.
"""
def __init__(self, pod_rank, rbf_kernel):
"""
"""
super().__init__()
self.pod = PODBlock(pod_rank)
self.rbf = RBFBlock(kernel=rbf_kernel)
def forward(self, x):
"""
Defines the computation performed at every call.
:param x: The tensor to apply the forward pass.
:type x: torch.Tensor
:return: the output computed by the model.
:rtype: torch.Tensor
"""
coefficents = self.rbf(x)
return self.pod.expand(coefficents)
def fit(self, p, x):
"""
Call the :meth:`pina.model.layers.PODBlock.fit` method of the
:attr:`pina.model.layers.PODBlock` attribute to perform the POD,
and the :meth:`pina.model.layers.RBFBlock.fit` method of the
:attr:`pina.model.layers.RBFBlock` attribute to fit the interpolation.
"""
self.pod.fit(x)
self.rbf.fit(p, self.pod.reduce(x))
We can then fit the model and ask it to predict the required field for
unseen values of the parameters. Note that this model does not need a
Trainer since it does not include any neural network or learnable
parameters.
pod_rbf = PODRBF(pod_rank=20, rbf_kernel='thin_plate_spline')
pod_rbf.fit(p_train, u_train)
u_test_rbf = pod_rbf(p_test)
u_train_rbf = pod_rbf(p_train)
relative_error_train = torch.norm(u_train_rbf - u_train)/torch.norm(u_train)
relative_error_test = torch.norm(u_test_rbf - u_test)/torch.norm(u_test)
print('Error summary for POD-RBF model:')
print(f' Train: {relative_error_train.item():e}')
print(f' Test: {relative_error_test.item():e}')
Error summary for POD-RBF model:
Train: 1.287801e-03
Test: 1.217041e-03
POD-NN reduced order model#
class PODNN(torch.nn.Module):
"""
Proper orthogonal decomposition with neural network model.
"""
def __init__(self, pod_rank, layers, func):
"""
"""
super().__init__()
self.pod = PODBlock(pod_rank)
self.nn = FeedForward(
input_dimensions=1,
output_dimensions=pod_rank,
layers=layers,
func=func
)
def forward(self, x):
"""
Defines the computation performed at every call.
:param x: The tensor to apply the forward pass.
:type x: torch.Tensor
:return: the output computed by the model.
:rtype: torch.Tensor
"""
coefficents = self.nn(x)
return self.pod.expand(coefficents)
def fit_pod(self, x):
"""
Just call the :meth:`pina.model.layers.PODBlock.fit` method of the
:attr:`pina.model.layers.PODBlock` attribute.
"""
self.pod.fit(x)
We highlight that the POD modes are directly computed by means of the singular value decomposition (computed over the input data), and not trained using the backpropagation approach. Only the weights of the MLP are actually trained during the optimization loop.
pod_nn = PODNN(pod_rank=20, layers=[10, 10, 10], func=torch.nn.Tanh)
pod_nn.fit_pod(u_train)
pod_nn_stokes = SupervisedSolver(
problem=poisson_problem,
model=pod_nn,
optimizer=torch.optim.Adam,
optimizer_kwargs={'lr': 0.0001})
Now that we have set the Problem and the Model, we have just to
train the model and use it for predicting the test snapshots.
trainer = Trainer(
solver=pod_nn_stokes,
max_epochs=1000,
batch_size=100,
log_every_n_steps=5,
accelerator='cpu')
trainer.train()
GPU available: True (cuda), used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/u/a/aivagnes/anaconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/setup.py:187: GPU available but not used. You can set it by doing Trainer(accelerator='gpu').
| Name | Type | Params
----------------------------------------
0 | _loss | MSELoss | 0
1 | _neural_net | Network | 460
----------------------------------------
460 Trainable params
0 Non-trainable params
460 Total params
0.002 Total estimated model params size (MB)
/u/a/aivagnes/anaconda3/lib/python3.8/site-packages/torch/cuda/__init__.py:152: UserWarning:
Found GPU0 Quadro K600 which is of cuda capability 3.0.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability supported by this library is 3.7.
warnings.warn(old_gpu_warn % (d, name, major, minor, min_arch // 10, min_arch % 10))
Training: | | 0/? [00:00<?, ?it/s]
Trainer.fit stopped: max_epochs=1000 reached.
Done! Now that the computational expensive part is over, we can load in
future the model to infer new parameters (simply loading the checkpoint
file automatically created by Lightning) or test its performances.
We measure the relative error for the training and test datasets,
printing the mean one.
u_test_nn = pod_nn_stokes(p_test)
u_train_nn = pod_nn_stokes(p_train)
relative_error_train = torch.norm(u_train_nn - u_train)/torch.norm(u_train)
relative_error_test = torch.norm(u_test_nn - u_test)/torch.norm(u_test)
print('Error summary for POD-NN model:')
print(f' Train: {relative_error_train.item():e}')
print(f' Test: {relative_error_test.item():e}')
Error summary for POD-NN model:
Train: 3.767902e-02
Test: 3.488588e-02
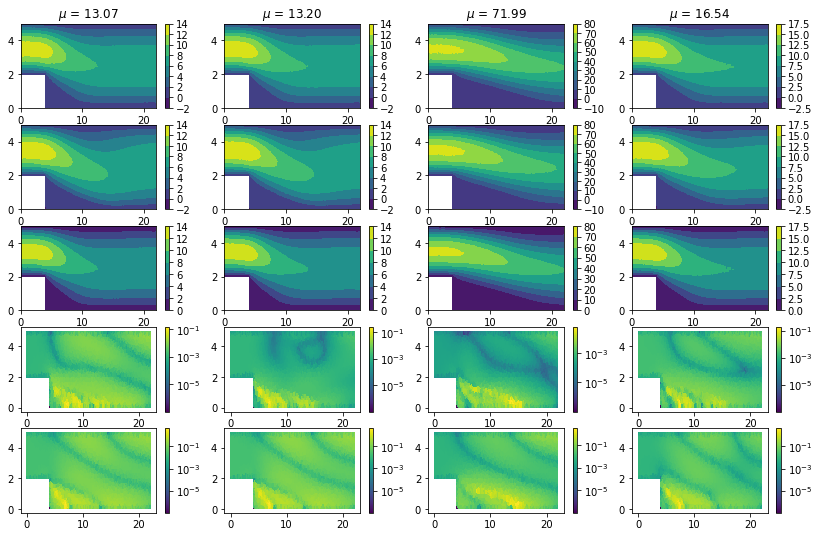
POD-RBF vs POD-NN#
We can of course also plot the solutions predicted by the PODRBF and
by the PODNN model, comparing them to the original ones. We can note
here, in the PODNN model and for low velocities, some differences,
but improvements can be accomplished thanks to longer training.
idx = torch.randint(0, len(u_test), (4,))
u_idx_rbf = pod_rbf(p_test[idx])
u_idx_nn = pod_nn_stokes(p_test[idx])
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
fig, axs = plt.subplots(5, 4, figsize=(14, 9))
relative_error_rbf = np.abs(u_test[idx] - u_idx_rbf.detach())
relative_error_rbf = np.where(u_test[idx] < 1e-7, 1e-7, relative_error_rbf/u_test[idx])
relative_error_nn = np.abs(u_test[idx] - u_idx_nn.detach())
relative_error_nn = np.where(u_test[idx] < 1e-7, 1e-7, relative_error_nn/u_test[idx])
for i, (idx_, rbf_, nn_, rbf_err_, nn_err_) in enumerate(
zip(idx, u_idx_rbf, u_idx_nn, relative_error_rbf, relative_error_nn)):
axs[0, i].set_title(f'$\mu$ = {p_test[idx_].item():.2f}')
cm = axs[0, i].tricontourf(dataset.triang, rbf_.detach()) # POD-RBF prediction
plt.colorbar(cm, ax=axs[0, i])
cm = axs[1, i].tricontourf(dataset.triang, nn_.detach()) # POD-NN prediction
plt.colorbar(cm, ax=axs[1, i])
cm = axs[2, i].tricontourf(dataset.triang, u_test[idx_].flatten()) # Truth
plt.colorbar(cm, ax=axs[2, i])
cm = axs[3, i].tripcolor(dataset.triang, rbf_err_, norm=matplotlib.colors.LogNorm()) # Error for POD-RBF
plt.colorbar(cm, ax=axs[3, i])
cm = axs[4, i].tripcolor(dataset.triang, nn_err_, norm=matplotlib.colors.LogNorm()) # Error for POD-NN
plt.colorbar(cm, ax=axs[4, i])
plt.show()