Tutorial: PINA and PyTorch Lightning, training tips and visualizations#
![]()
In this tutorial, we will delve deeper into the functionality of the
Trainer class, which serves as the cornerstone for training PINA
Solvers.
The Trainer class offers a plethora of features aimed at improving
model accuracy, reducing training time and memory usage, facilitating
logging visualization, and more thanks to the amazing job done by the PyTorch Lightning team!
Our leading example will revolve around solving the SimpleODE
problem, as outlined in the Introduction to PINA for Physics Informed
Neural Networks
training.
If you haven’t already explored it, we highly recommend doing so before
diving into this tutorial.
Let’s start by importing useful modules, define the SimpleODE
problem and the PINN solver.
## routine needed to run the notebook on Google Colab
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False
if IN_COLAB:
!pip install "pina-mathlab"
import torch
from pina import Condition, Trainer
from pina.solvers import PINN
from pina.model import FeedForward
from pina.problem import SpatialProblem
from pina.operators import grad
from pina.geometry import CartesianDomain
from pina.equation import Equation, FixedValue
class SimpleODE(SpatialProblem):
output_variables = ['u']
spatial_domain = CartesianDomain({'x': [0, 1]})
# defining the ode equation
def ode_equation(input_, output_):
u_x = grad(output_, input_, components=['u'], d=['x'])
u = output_.extract(['u'])
return u_x - u
# conditions to hold
conditions = {
'x0': Condition(location=CartesianDomain({'x': 0.}), equation=FixedValue(1)), # We fix initial condition to value 1
'D': Condition(location=CartesianDomain({'x': [0, 1]}), equation=Equation(ode_equation)), # We wrap the python equation using Equation
}
# defining the true solution
def truth_solution(self, pts):
return torch.exp(pts.extract(['x']))
# sampling for training
problem = SimpleODE()
problem.discretise_domain(1, 'random', locations=['x0'])
problem.discretise_domain(20, 'lh', locations=['D'])
# build the model
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
# create the PINN object
pinn = PINN(problem, model)
Till now we just followed the extact step of the previous tutorials. The
Trainer object can be initialized by simiply passing the PINN
solver
trainer = Trainer(solver=pinn)
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Trainer Accelerator#
When creating the trainer, by defualt the Trainer will choose
the most performing accelerator for training which is available in
your system, ranked as follow:
For setting manually the accelerator run:
accelerator = {'gpu', 'cpu', 'hpu', 'mps', 'cpu', 'ipu'}sets the accelerator to a specific one
trainer = Trainer(solver=pinn,
accelerator='cpu')
GPU available: True (mps), used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
as you can see, even if in the used system GPU is available, it is
not used since we set accelerator='cpu'.
Trainer Logging#
In PINA you can log metrics in different ways. The simplest approach
is to use the MetricTraker class from pina.callbacks as seen in
the Introduction to PINA for Physics Informed Neural Networks
training
tutorial.
However, expecially when we need to train multiple times to get an
average of the loss across multiple runs, pytorch_lightning.loggers
might be useful. Here we will use TensorBoardLogger (more on
logging
here), but you can choose the one you prefer (or make your own one).
We will now import TensorBoardLogger, do three runs of training and
then visualize the results. Notice we set enable_model_summary=False
to avoid model summary specifications (e.g. number of parameters), set
it to true if needed.
from pytorch_lightning.loggers import TensorBoardLogger
# three run of training, by default it trains for 1000 epochs
# we reinitialize the model each time otherwise the same parameters will be optimized
for _ in range(3):
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
logger=TensorBoardLogger(save_dir='simpleode'),
enable_model_summary=False)
trainer.train()
GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Trainer.fit stopped: max_epochs=1000 reached. Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 133.46it/s, v_num=6, x0_loss=1.48e-5, D_loss=0.000655, mean_loss=0.000335]
GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Trainer.fit stopped: max_epochs=1000 reached. Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 154.49it/s, v_num=7, x0_loss=6.21e-6, D_loss=0.000221, mean_loss=0.000114]
GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Trainer.fit stopped: max_epochs=1000 reached. Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 62.60it/s, v_num=8, x0_loss=1.44e-5, D_loss=0.000572, mean_loss=0.000293]
We can now visualize the logs by simply running
tensorboard --logdir=simpleode/ on terminal, you should obtain a
webpage as the one shown below:
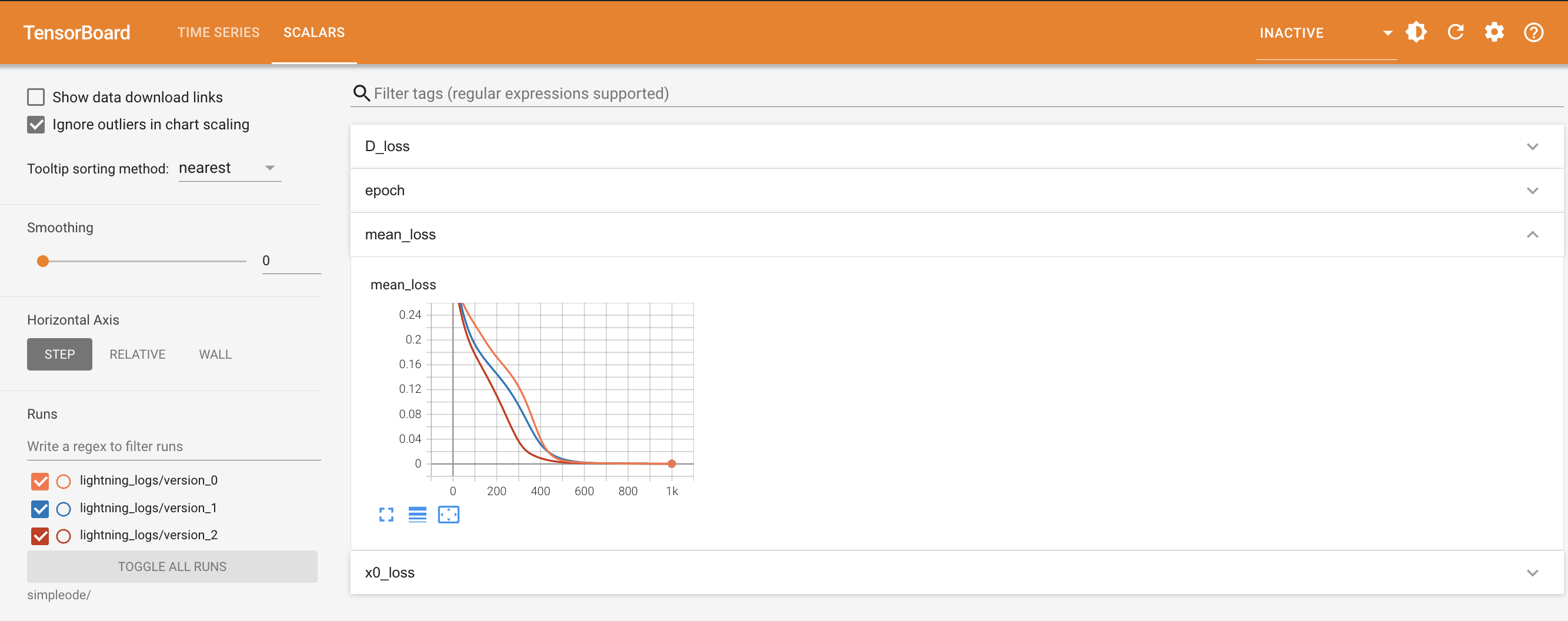
as you can see, by default, PINA logs the losses which are shown in the progress bar, as well as the number of epochs. You can always insert more loggings by either defining a callback (more on callbacks), or inheriting the solver and modify the programs with different hooks (more on hooks).
Trainer Callbacks#
Whenever we need to access certain steps of the training for logging, do
static modifications (i.e. not changing the Solver) or updating
Problem hyperparameters (static variables), we can use
Callabacks. Notice that Callbacks allow you to add arbitrary
self-contained programs to your training. At specific points during the
flow of execution (hooks), the Callback interface allows you to design
programs that encapsulate a full set of functionality. It de-couples
functionality that does not need to be in PINA Solvers.
Lightning has a callback system to execute them when needed. Callbacks
should capture NON-ESSENTIAL logic that is NOT required for your
lightning module to run.
The following are best practices when using/designing callbacks.
Callbacks should be isolated in their functionality.
Your callback should not rely on the behavior of other callbacks in order to work properly.
Do not manually call methods from the callback.
Directly calling methods (eg. on_validation_end) is strongly discouraged.
Whenever possible, your callbacks should not depend on the order in which they are executed.
We will try now to implement a naive version of MetricTraker to show
how callbacks work. Notice that this is a very easy application of
callbacks, fortunately in PINA we already provide more advanced
callbacks in pina.callbacks.
from pytorch_lightning.callbacks import Callback
import torch
# define a simple callback
class NaiveMetricTracker(Callback):
def __init__(self):
self.saved_metrics = []
def on_train_epoch_end(self, trainer, __): # function called at the end of each epoch
self.saved_metrics.append(
{key: value for key, value in trainer.logged_metrics.items()}
)
Let’s see the results when applyed to the SimpleODE problem. You can
define callbacks when initializing the Trainer by the callbacks
argument, which expects a list of callbacks.
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
enable_model_summary=False,
callbacks=[NaiveMetricTracker()]) # adding a callbacks
trainer.train()
GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Trainer.fit stopped: max_epochs=1000 reached. Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 149.27it/s, v_num=1, x0_loss=7.27e-5, D_loss=0.0016, mean_loss=0.000838]
We can easily access the data by calling
trainer.callbacks[0].saved_metrics (notice the zero representing the
first callback in the list given at initialization).
trainer.callbacks[0].saved_metrics[:3] # only the first three epochs
[{'x0_loss': tensor(0.9141),
'D_loss': tensor(0.0304),
'mean_loss': tensor(0.4722)},
{'x0_loss': tensor(0.8906),
'D_loss': tensor(0.0287),
'mean_loss': tensor(0.4596)},
{'x0_loss': tensor(0.8674),
'D_loss': tensor(0.0274),
'mean_loss': tensor(0.4474)}]
PyTorch Lightning also has some built in Callbacks which can be used
in PINA, here an extensive
list.
We can for example try the EarlyStopping routine, which
automatically stops the training when a specific metric converged (here
the mean_loss). In order to let the training keep going forever set
max_epochs=-1.
# ~2 mins
from pytorch_lightning.callbacks import EarlyStopping
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
max_epochs = -1,
enable_model_summary=False,
callbacks=[EarlyStopping('mean_loss')]) # adding a callbacks
trainer.train()
GPU available: True (mps), used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Epoch 6157: 100%|██████████| 1/1 [00:00<00:00, 139.84it/s, v_num=9, x0_loss=4.21e-9, D_loss=9.93e-6, mean_loss=4.97e-6]
As we can see the model automatically stop when the logging metric stopped improving!
Trainer Tips to Boost Accuracy, Save Memory and Speed Up Training#
Untill now we have seen how to choose the right accelerator, how to
log and visualize the results, and how to interface with the program in
order to add specific parts of code at specific points by callbacks.
Now, we well focus on how boost your training by saving memory and
speeding it up, while mantaining the same or even better degree of
accuracy!
There are several built in methods developed in PyTorch Lightning which can be applied straight forward in PINA, here we report some:
Stochastic Weight Averaging to boost accuracy
Gradient Clippling to reduce computational time (and improve accuracy)
Gradient Accumulation to save memory consumption
Mixed Precision Training to save memory consumption
We will just demonstrate how to use the first two, and see the results
compared to a standard training. We use the
Timer
callback from pytorch_lightning.callbacks to take the times. Let’s
start by training a simple model without any optimization (train for
2000 epochs).
from pytorch_lightning.callbacks import Timer
from pytorch_lightning import seed_everything
# setting the seed for reproducibility
seed_everything(42, workers=True)
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
deterministic=True, # setting deterministic=True ensure reproducibility when a seed is imposed
max_epochs = 2000,
enable_model_summary=False,
callbacks=[Timer()]) # adding a callbacks
trainer.train()
print(f'Total training time {trainer.callbacks[0].time_elapsed("train"):.5f} s')
Seed set to 42 GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Trainer.fit stopped: max_epochs=2000 reached. Epoch 1999: 100%|██████████| 1/1 [00:00<00:00, 163.58it/s, v_num=31, x0_loss=1.12e-6, D_loss=0.000127, mean_loss=6.4e-5] Total training time 17.36381 s
Now we do the same but with StochasticWeightAveraging
from pytorch_lightning.callbacks import StochasticWeightAveraging
# setting the seed for reproducibility
seed_everything(42, workers=True)
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
deterministic=True,
max_epochs = 2000,
enable_model_summary=False,
callbacks=[Timer(),
StochasticWeightAveraging(swa_lrs=0.005)]) # adding StochasticWeightAveraging callbacks
trainer.train()
print(f'Total training time {trainer.callbacks[0].time_elapsed("train"):.5f} s')
Seed set to 42 GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Epoch 1598: 100%|██████████| 1/1 [00:00<00:00, 210.04it/s, v_num=47, x0_loss=4.17e-6, D_loss=0.000204, mean_loss=0.000104] Swapping scheduler ConstantLR for SWALR Trainer.fit stopped: max_epochs=2000 reached. Epoch 1999: 100%|██████████| 1/1 [00:00<00:00, 120.85it/s, v_num=47, x0_loss=1.56e-7, D_loss=7.49e-5, mean_loss=3.75e-5] Total training time 17.10627 s
As you can see, the training time does not change at all! Notice that
around epoch 1600 the scheduler is switched from the defalut one
ConstantLR to the Stochastic Weight Average Learning Rate
(SWALR). This is because by default StochasticWeightAveraging
will be activated after int(swa_epoch_start * max_epochs) with
swa_epoch_start=0.7 by default. Finally, the final mean_loss is
lower when StochasticWeightAveraging is used.
We will now now do the same but clippling the gradient to be relatively small.
# setting the seed for reproducibility
seed_everything(42, workers=True)
model = FeedForward(
layers=[10, 10],
func=torch.nn.Tanh,
output_dimensions=len(problem.output_variables),
input_dimensions=len(problem.input_variables)
)
pinn = PINN(problem, model)
trainer = Trainer(solver=pinn,
accelerator='cpu',
max_epochs = 2000,
enable_model_summary=False,
gradient_clip_val=0.1, # clipping the gradient
callbacks=[Timer(),
StochasticWeightAveraging(swa_lrs=0.005)])
trainer.train()
print(f'Total training time {trainer.callbacks[0].time_elapsed("train"):.5f} s')
Seed set to 42 GPU available: True (mps), used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs Epoch 1598: 100%|██████████| 1/1 [00:00<00:00, 261.80it/s, v_num=46, x0_loss=9e-8, D_loss=2.39e-5, mean_loss=1.2e-5] Swapping scheduler ConstantLR for SWALR Trainer.fit stopped: max_epochs=2000 reached. Epoch 1999: 100%|██████████| 1/1 [00:00<00:00, 148.99it/s, v_num=46, x0_loss=7.08e-7, D_loss=1.77e-5, mean_loss=9.19e-6] Total training time 17.01149 s
As we can see we by applying gradient clipping we were able to even obtain lower error!
What’s next?#
Now you know how to use efficiently the Trainer class PINA!
There are multiple directions you can go now:
Explore training times on different devices (e.g.)
TPUTry to reduce memory cost by mixed precision training and gradient accumulation (especially useful when training Neural Operators)
Benchmark
Trainerspeed for different precisions.